Cloud Detection and Response (CDR) unifies multi-cloud and identity telemetry (CloudTrail/Azure/GCP logs, IAM, Kubernetes, workload signals) to surface high-fidelity detections and orchestrate governed, auditable actions. In 2025—amid identity-driven attacks and ephemeral compute—CDR reduces dwell time, MTTD, and MTTR with human-in-the-loop automation. This guide explains what CDR is, how it works, a reference architecture, a phased rollout, the KPIs that matter, and pitfalls to avoid.
Introduction
Cloud estates have outgrown traditional monitoring. Containers spin up and vanish in seconds; serverless functions appear only long enough to handle an event; identities, roles, and entitlements shift hourly. Against that backdrop, cloud detection and response gives security teams the continuous visibility and governed automation they need to keep pace.
Teams aren’t short on data. They’re drowning in it—CloudTrail and Azure Activity logs, GCP Audit logs, workload telemetry, Kubernetes audit streams, identity signals, and network flows. What’s scarce is a system that converts all that noise into prioritized, explainable detections and safe, repeatable responses.
Enter CDR: a way to unify multi‑cloud telemetry, map behaviors to MITRE ATT&CK techniques, and take precise, auditable actions that reduce MTTD, MTTR, and dwell time—without over‑automating. This guide explains the fundamentals and how to implement CDR in a way that scales.
Definition: Cloud Detection and Response (CDR)
Cloud Detection and Response (CDR) is a security practice and toolchain that continuously ingests cloud and identity telemetry, detects suspicious behaviors using rules and analytics, and orchestrates governed, auditable responses (manual or automated) across multi‑cloud environments—reducing dwell time and operational risk while preserving developer velocity.
Key Takeaways
- What it is: CDR unifies cloud telemetry and response to stop attacks across IaaS, PaaS, containers, and serverless.
- How it works: Ingest → detect → triage → respond → improve, aligned to MITRE ATT&CK and NIST incident handling.
- Why it matters: Multi‑cloud complexity and identity abuse demand real‑time detection and automated cloud response with guardrails.
- Results: Lower MTTD/MTTR, reduced false positives, measured coverage, and shorter dwell time.
- Scope: High‑level architecture and roadmap—no vendor lists or step‑by‑steps here.
- Next reads: CDR vs. XDR: Key Differences and Building a Cloud Detection & Response Architecture.
Why CDR Matters in 2025
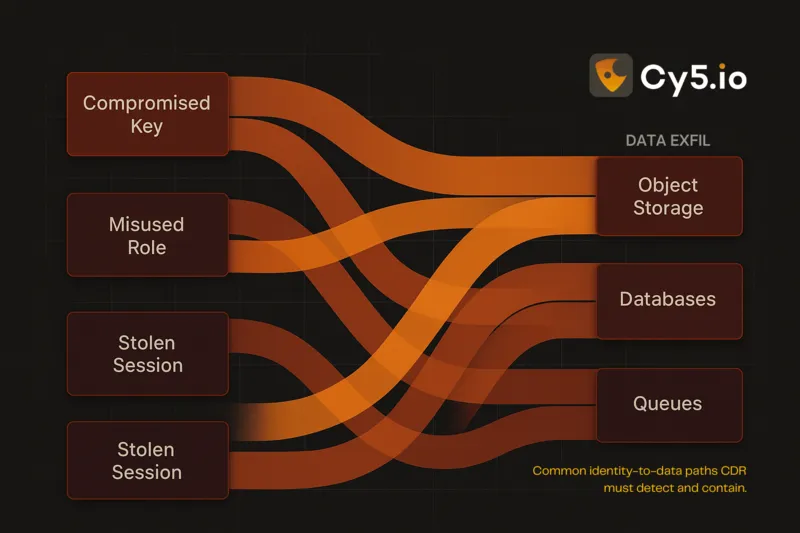
Cloud attack surfaces evolve faster than static controls. Identities and permissions sprawl. Ephemeral workloads defeat legacy sensors. Data leaves through indirect paths—misconfigured storage, compromised tokens, or abused roles. CDR addresses these realities by correlating identity, workload, and control‑plane behaviors in near real time.
Frameworks help. MITRE ATT&CK provides a common language for detection engineering (for example, suspicious role escalation or access key abuse in cloud contexts), while NIST incident response principles (e.g., NIST SP 800‑61) guide preparation, detection/analysis, containment, eradication, and recovery. Together, they anchor CDR to standards while leaving room for platform nuance.
References: MITRE ATT&CK • NIST SP 800‑61 Rev. 2
If you’re comparing categories: CDR focuses on cloud control planes, identities, and ephemeral compute; XDR often broadens to endpoints and networks.
How Cloud Detection and Response Works
Telemetry Ingestion
Aggregate cloud provider logs (AWS CloudTrail, Azure Activity, GCP Audit), workload telemetry (CWPP/EDR where feasible), identity/IAM events, Kubernetes and container audit logs, and network signals. Normalize and timestamp at ingest to keep queries and correlations fast.
Detection
Blend rules, behavioral analytics, and machine learning cloud detection to catch known and unknown patterns. Map detections to ATT&CK tactics/techniques for traceability. Emphasize explainability: analysts should see why something triggered, with evidence and rationale.
Triage & Enrichment
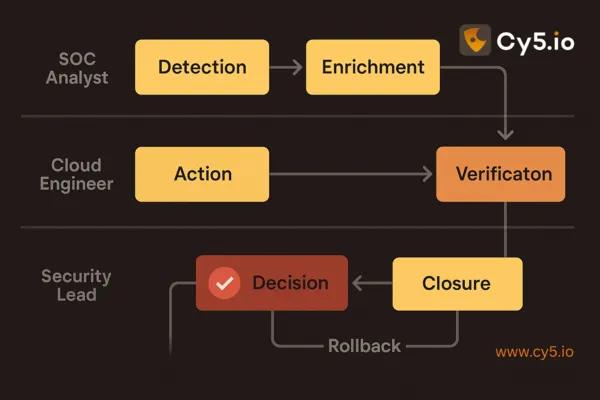
Enrich alerts with asset tags, identity context, recent changes, and business criticality. Assign confidence scores and route via case management. Use playbooks to standardize decisions and reduce swivel‑chair work across SIEM/CNAPP/SOAR.

Response
Prefer human‑in‑the‑loop actions for risky changes; automate low‑risk steps with guardrails (e.g., temporary session revocation, policy rollback, isolating a workload). Integrate with SOAR to coordinate tickets, approvals, and communications.
Continuous Improvement
Close the loop with threat intel, purple‑team findings, post‑incident reviews, and drift detection. Promote high‑value detections, retire noisy ones, and track metrics over time.

Core CDR Capabilities & Outcomes
Effective programs balance coverage (IaaS, PaaS, Kubernetes, serverless) with depth (identity analytics, workload protection, data egress monitoring). This enables real‑time cloud threat detection and automated cloud response where safe.
CDR Capability → Operational Outcome
| CDR Capability | Operational Outcome |
| Identity anomaly detection (role misuse, key abuse) | Reduced dwell time; faster containment of identity threats |
| Control‑plane change monitoring | Early detection of persistence & privilege escalation |
| Baseline + behavioral analytics | Lower false positives; higher analyst confidence |
| Kubernetes/serverless visibility | Fewer blind spots in ephemeral compute |
| Data egress & public exposure guards | Reduced exfiltration risk; compliance support |
| Guided playbooks & SOAR actions | Consistent response; lower MTTR |
| Post‑incident learning loops | Continuous detection quality improvement |

High‑Level CDR Architecture
Reference path: Data sources → Normalization & storage → Detection engine (rules/ML mapped to ATT&CK) → Case management/SOAR → Governed responders (rollback, revoke, isolate) → Evidence/forensics store. Keep components loosely coupled to avoid lock‑in and enable multi‑cloud scale.
Implementation Roadmap
Phase 0: Readiness
- Establish logging baselines for each cloud; verify retention and integrity.
- Fix identity hygiene: least privilege, MFA/strong auth, key rotation.
- Define high‑value assets and business context tags.
Phase 1: Minimum Viable Detections
- Start with the top 10 ATT&CK techniques most relevant to your environment (e.g., suspicious role elevation, credential misuse, anomalous API usage).
- Write rules with clear, testable hypotheses and evidence output.
- Validate with tabletop and replayed logs.
Phase 2: Automations with Guardrails
- Automate low‑risk responses (e.g., quarantine a container namespace, revoke ephemeral credentials).
- Require approvals for high‑impact actions; implement rollback and change logs.
- Track % automated closures and measure effect on MTTR.
Phase 3: Scale & Optimize
- Suppress noise through entity risk scoring, asset criticality, and deduplication.
- Add drift detection for policies and identities.
- Quarterly KPI reviews with stakeholders; publish a change log for transparency.
- Document cloud detection best practices and maintain them as living standards.

Measuring CDR Effectiveness
Define KPIs that reflect outcomes, not just activity:
- Coverage % across data sources and services.
- MTTD/MTTR (mean time to detect/respond) and mean time to containment.
- Dwell time trend: median hours from initial suspicious event to containment.
- False‑positive rate and precision/recall for analytics‑driven detections.
- % automated closures with guardrails; rollback frequency.
- Analyst effort saved (tickets avoided, hours reclaimed) and escalation rate.
Example targets (calibrate to your risk):
- Coverage ≥ 85% of critical services; MTTD ≤ 15 minutes for priority identities; MTTR ≤ 60 minutes for high‑severity incidents; false‑positive rate < 10% for promoted detections.
Reporting up: Monthly one‑page briefing with KPI deltas, top lessons learned, and remediation themes.
Risks, Pitfalls, and How to Avoid Them
- Over‑automation: Triggering high‑impact changes without approvals can disrupt workloads. Use human‑in‑the‑loop and rollbacks.
- Serverless/K8s blind spots: Ensure you capture function and pod‑level telemetry with context (namespace, service account, image hash).
- Identity misconfigurations: Excessive permissions and stale roles are common root causes. Enforce least privilege and monitor role changes.
- Alert fatigue: Promote high‑signal detections, retire weak ones, and enrich with business context to prioritize what matters.
- Siloed tooling: Integrate with SIEM/SOAR and case management to avoid fragmented response.
FAQs: Cloud Detection and Response
Cloud detection and response (CDR) unifies cloud and identity telemetry to spot suspicious behavior and coordinate governed responses (manual or automated) across multi‑cloud environments. The goal is to reduce dwell time while maintaining developer speed.
EDR focuses on endpoints; XDR spans endpoints, network, and more. CDR zeroes in on cloud control planes, identities, and ephemeral compute.
Cloud control‑plane logs (e.g., CloudTrail, Azure Activity, GCP Audit), identity/IAM events, workload telemetry (containers, serverless where feasible), Kubernetes audit logs, and selective network flows.
No. SIEM centralizes and retains data; SOAR orchestrates process and automation. CDR complements both by supplying cloud‑specific detections and governed actions.
Identity abuse (stolen or misused credentials), privilege escalation, persistence via rogue policies, anomalous API usage, suspicious container or serverless activity, and data egress anomalies mapped to MITRE ATT&CK.
Automate low‑risk actions (revoke token, quarantine workload). Require approvals for high‑impact steps (role changes, service disruption). Track rollback rates to calibrate trust.
Coverage %, MTTD/MTTR, dwell time trend, false‑positive rate, % automated closures, analyst hours saved, and the rate of repeated incidents after corrective action.
Conclusion
Cloud detection and response is now table stakes for modern security teams. By unifying telemetry, grounding detections in ATT&CK, and executing governed automation, you’ll measurably reduce dwell time and risk while protecting developer velocity.